Abstract
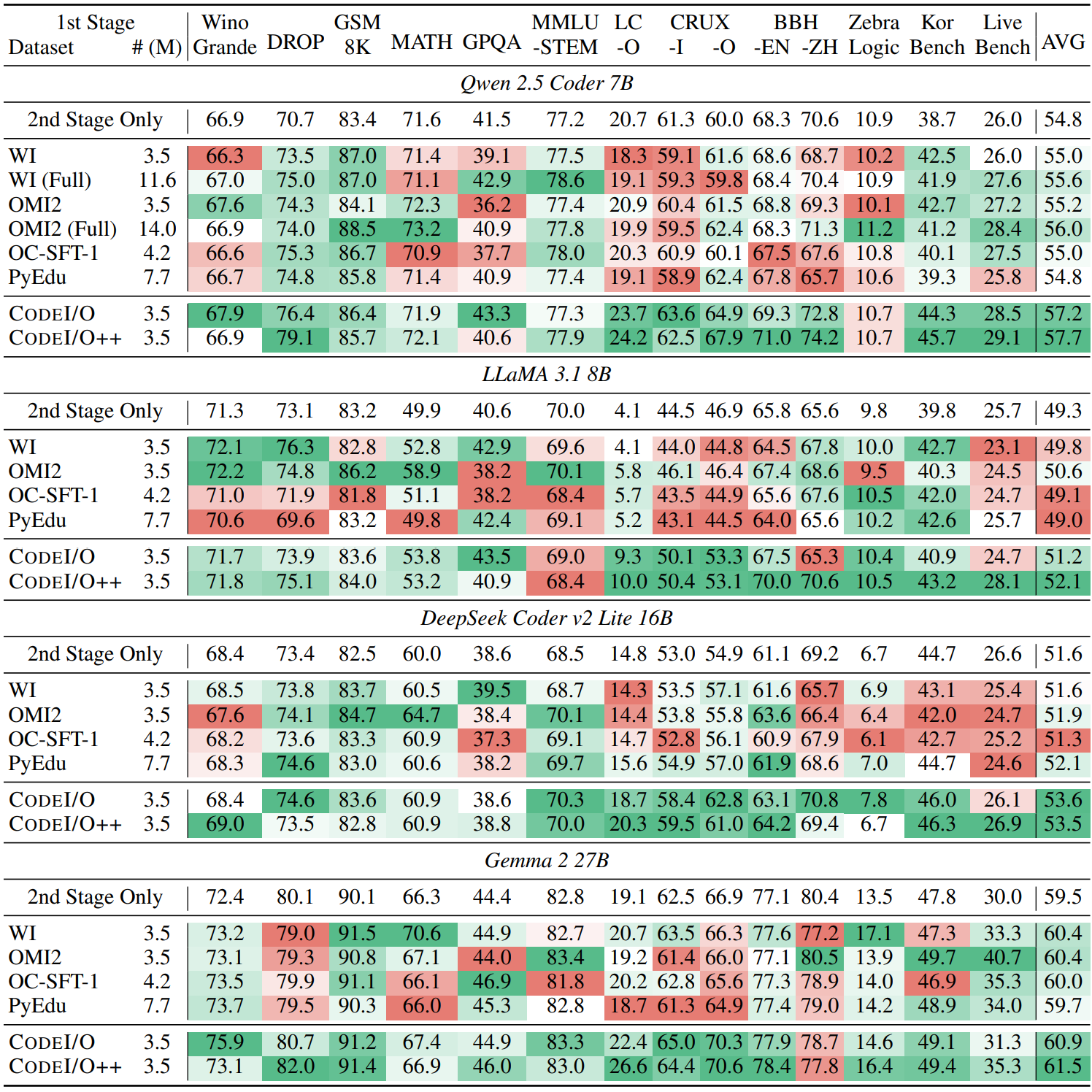
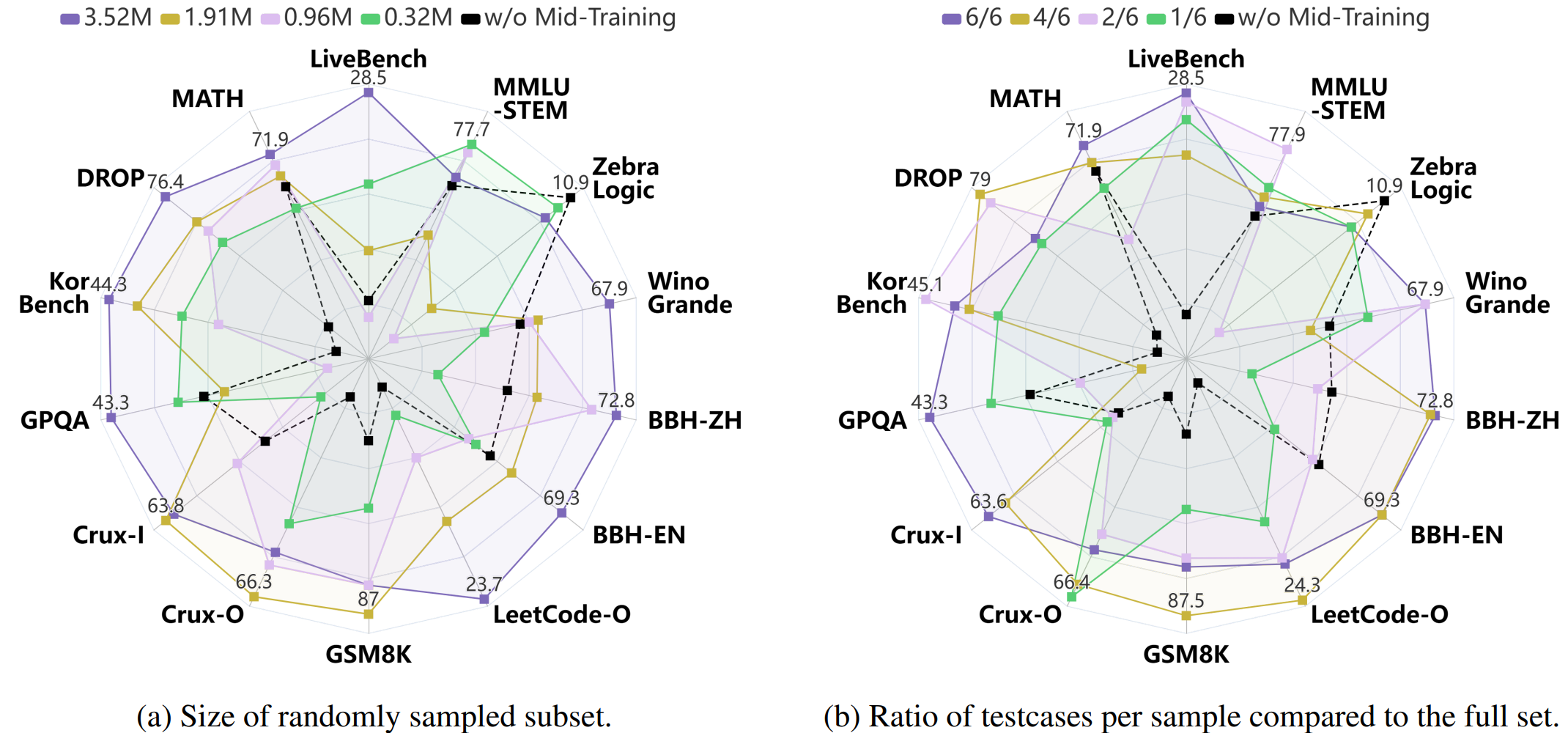
CodeI/O is a novel approach that transforms code-based reasoning patterns into natural language formats to enhance Large Language Models' reasoning capabilities. Unlike traditional methods focusing on specific skills, our approach systematically extracts universal reasoning primitives while maintaining procedural rigor, enabling better performance across various reasoning tasks.
Key Features & Contributions
- 🔄 Universal Transformation: Converts diverse code patterns into natural language Chain-of-Thought rationales
- 🧠 Syntax-Decoupled: Decouples reasoning from code syntax while preserving logical structure
- 📊 Multi-Task Enhancement: Improves performance across symbolic, scientific, logic, math, commonsense and code reasoning
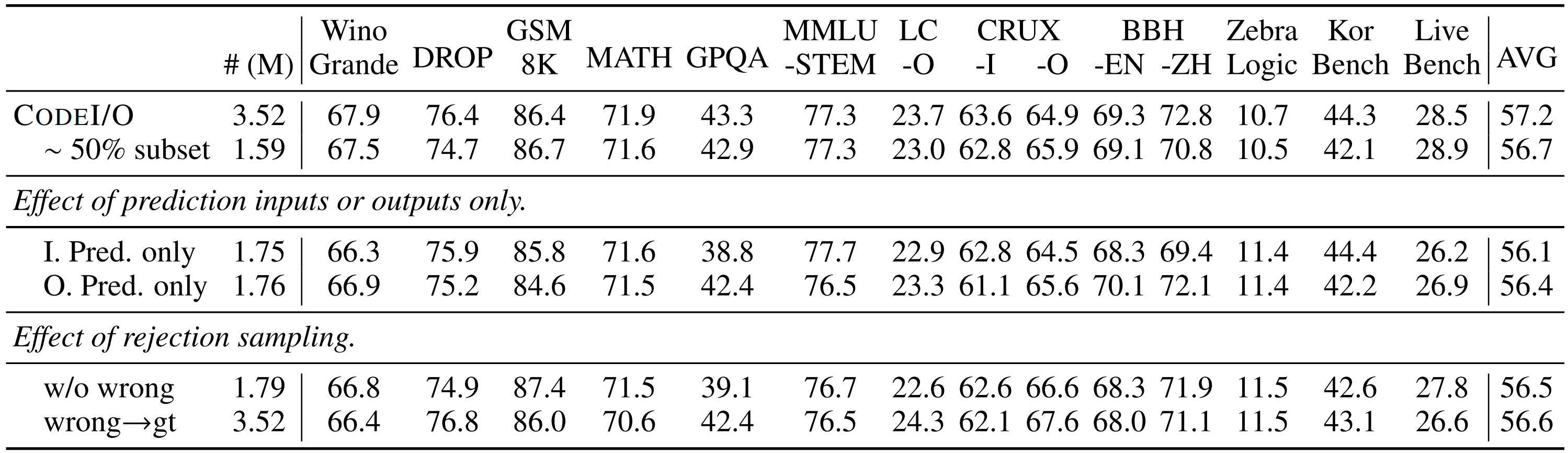
- ✨ Fully-Verifiable: Supports precise prediction verification through cached ground-truth matching or code re-execution
- 🚀 Advanced Iteration: Enhanced version (CodeI/O++) with multi-turn revision for better accuracy
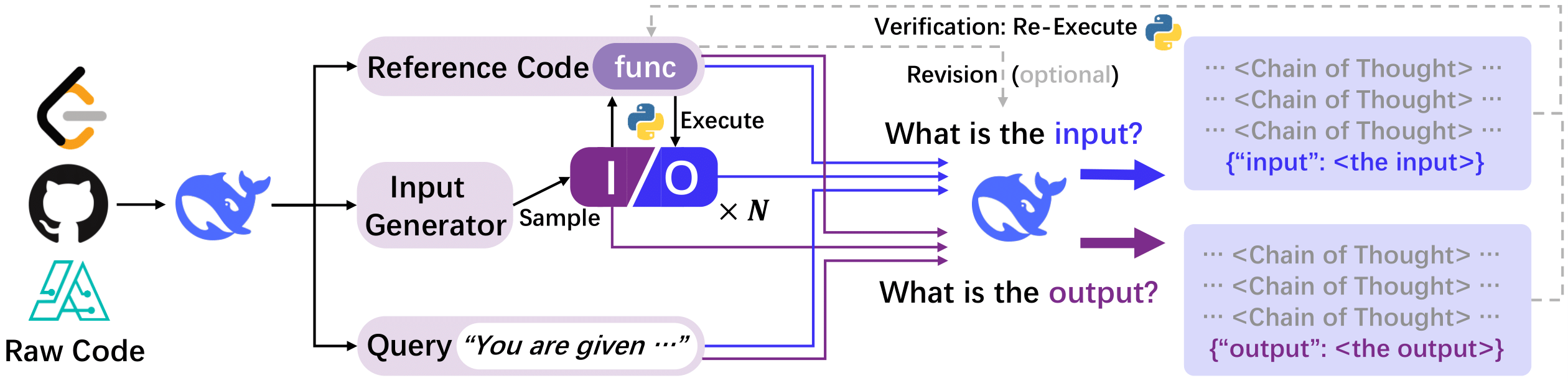
Core Data Construction Pipeline
We begin with collecting raw code files from various sources. They are then transformed into a unified format. Next, I/O pairs are sampled from the transformed functions through code execution. Finally, the complete training dataset is assembled, using both the elements in the unified format and responses collected from LLMs.